COMPOSE Hypergraph Cover Optimization for Multi-view 3D Human Pose Estimation
- Training-free
- Off-the-shelf 2D detectors
- ILP + BP
- ~5 ms per frame
Prior optimization methods match cameras pairwise and then stitch those matches together, which becomes brittle when views are occluded or noisy. COMPOSE instead matches each person across all views at once, framing the problem as a weighted exact cover over a hypergraph. An ILP solves it exactly, while Belief Propagation gives an answer in milliseconds on the GPU. No training is involved.
- 1 Technical University of Munich (TUM)
- 2 Munich Center for Machine Learning (MCML)
- 3 Imperial College London
COMPOSE matches whole multi-view hypotheses at once rather than stitching pairwise links, so it keeps the correspondences that pairwise methods lose under occlusion — and it trains nothing.
- Problem Matching cameras two at a time is fragile under occlusion and noisy detections. One bad local match can corrupt the whole global solution.
- Idea Match every detection at once as one weighted exact cover over a hypergraph of person hypotheses, instead of resolving view pairs one by one.
- Solvers Geometric pruning first trims the candidate hyperedges. An ILP then solves the cover exactly, or Belief Propagation solves it at scale on the GPU.
- Result state of the art among optimization-based methods, and ahead of recent self-supervised ones (numbers below).
Read the full abstract
3D human pose estimation from sparse multi-view camera rigs is an essential task for numerous applications, including action recognition, sports analysis, and human-robot interaction. While learned methods dominate the field on benchmarks, they require large annotated datasets; training-free optimization-based methods remain promising as they circumvent 3D supervision by solving a correspondence problem across views from 2D detections.
Existing combinatorial formulations rely on pairwise associations to model this correspondence problem and enforce global consistency across views only as a downstream constraint. However, reconciling locally plausible pairwise matches becomes brittle under occlusion and noisy detections, where local errors propagate globally.
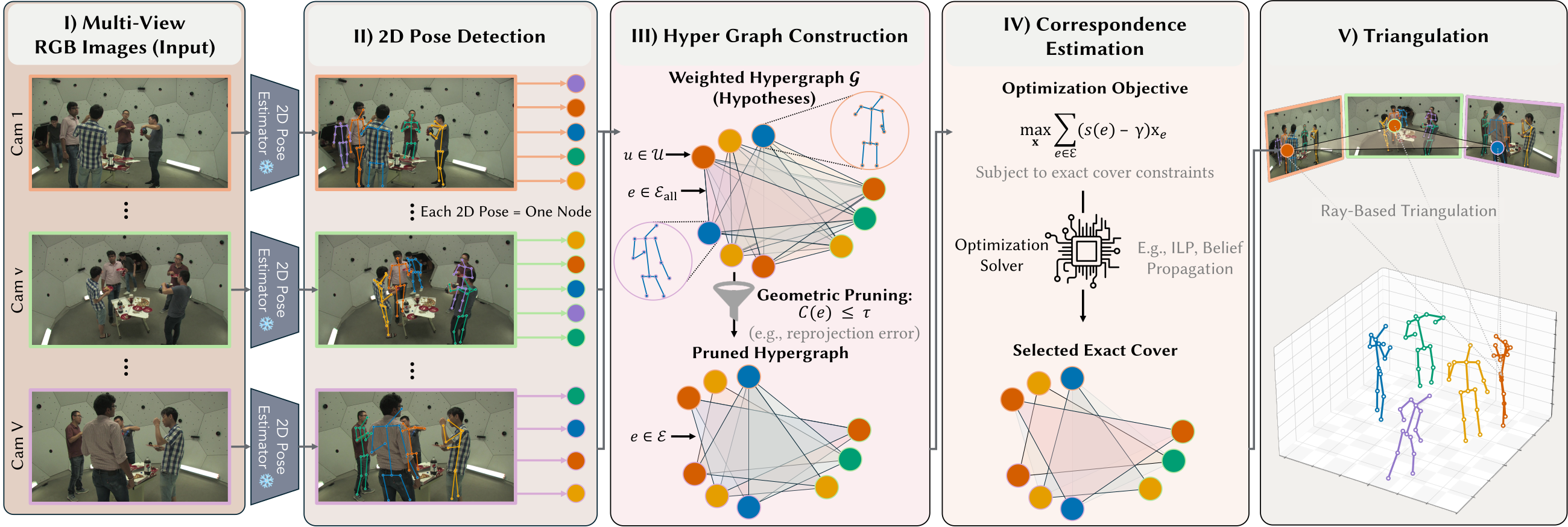
We propose COMPOSE, which recasts multi-view 3D human pose estimation as a weighted exact-cover optimization over a hypergraph of person hypotheses. Our formulation replaces pairwise association and post-hoc consistency enforcement with a single global combinatorial objective. To address the exponentially large candidate space, we introduce a geometric pruning strategy alongside two complementary solvers: an exact Integer Linear Programming formulation and a scalable relaxation via Belief Propagation.
Without any 3D supervision, COMPOSE improves average precision by up to 31 points over the best optimization-based method and 13 points over self-supervised learned methods, demonstrating the effectiveness of higher-order combinatorial association for training-free multi-view 3D human pose estimation.



Headline results on CMU Panoptic
Evaluated on CMU Panoptic with the same 2D detector as the strongest optimization baseline.
over the best optimization-based method (MvPose 37.63 → COMPOSE-BP 68.88)
over the self-supervised SelfPose3d (55.13)
MPJPE on CMU Panoptic — below the best optimization baseline (MvPose 26.46)
Method: a single global hypergraph cover
- Hypergraph construction. Each hyperedge picks one detection per camera view to form a single multi-view person hypothesis, giving a V-partite (V camera views) hypergraph over all detections.
- Geometric pruning. A memory-bounded builder grows the hypergraph level by level, avoiding the O((N+1)V) blow-up, and keeps only hyperedges whose multi-view reprojection cost stays low (reprojection cost C(e) below a threshold τ).
- Correspondence estimation. Choose a weighted exact cover that assigns every detection to one person, solved exactly by ILP or at scale by Belief Propagation.
- Triangulation. The chosen correspondences are ray-triangulated into 3D skeletons, using nothing beyond 2D detections and camera calibration.
COMPOSE-ILP exact
Finds the global optimum of the weighted exact cover with branch-and-cut Integer Linear Programming.
COMPOSE-BP scalable · GPU
Relaxes the same problem and runs it as loopy Belief Propagation in batched GPU tensor operations.
The full pipeline
Full benchmark results
The gain concentrates at AP25, the strictest threshold, where one wrong cross-view match ruins the pose — so precise association is exactly what COMPOSE buys: it nearly doubles the best optimization baseline there (37.63 → 68.88), while AP50 and up are already saturated.
| Method | AP25 ↑ | AP50 ↑ | AP100 ↑ | AP150 ↑ | R@500 ↑ | MPJPE ↓ |
|---|---|---|---|---|---|---|
| Fully-supervised | ||||||
| Plane Sweep Pose | 92.12 | 98.96 | 99.81 | 99.84 | — | 16.78 |
| Wu et al. | 93.93 | 98.93 | 99.78 | 99.90 | 99.97 | 15.63 |
| TEMPO | 89.01 | 99.08 | 99.76 | 99.93 | — | 14.68 |
| VoxelPose + 3DSA | 94.20 | 98.49 | 99.21 | 99.31 | — | 13.98 |
| Self-supervised | ||||||
| SelfPose3d | 55.13 | 96.44 | 98.46 | 98.98 | 99.60 | 24.47 |
| DSP (†, 9 temporal frames) | 57.60 | 86.10 | 94.00 | — | — | 23.10 |
| Optimization-based (training-free) | ||||||
| ACTOR | — | — | — | — | — | 168.40 |
| MvPose (‡, same 2D detector) | 37.63 | 95.70 | 97.84 | 98.28 | 99.60 | 26.46 |
| COMPOSE-ILP Ours | 66.70 | 98.23 | 99.43 | 99.62 | 99.81 | 22.78 |
| COMPOSE-BP Ours | 68.88 | 98.37 | 99.42 | 99.61 | 99.81 | 22.78 |
† DSP uses 9 temporal frames. ‡ MvPose uses the same 2D detector as COMPOSE. ▲ = best among optimization-based methods. R@500 = Recall@500 mm.
On the sparse 4-view CMU3 setup, COMPOSE reaches 74.43 mAP, beating the self-supervised SelfPose3d (61.43) without training a pose model of its own.
| Method | CMU1 (7 cams) | CMU2 (7 cams) | CMU3 (4 cams) | CMU4 (4 cams) | ||||
|---|---|---|---|---|---|---|---|---|
| mAP ↑ | R@500 ↑ | mAP ↑ | R@500 ↑ | mAP ↑ | R@500 ↑ | mAP ↑ | R@500 ↑ | |
| Self-supervised | ||||||||
| SelfPose3d | 74.50 | 97.98 | 59.06 | 94.32 | 61.43 | 83.96 | 62.85 | 98.32 |
| Optimization-based | ||||||||
| MvPose | 84.62 | 99.53 | 80.07 | 99.37 | 59.74 | 98.80 | 74.85 | 98.59 |
| COMPOSE-ILP Ours | 88.49 | 99.61 | 84.45 | 99.58 | 73.83 | 98.40 | 80.17 | 99.31 |
| COMPOSE-BP Ours | 88.10 | 99.45 | 84.34 | 99.41 | 74.43 | 98.39 | 79.60 | 99.31 |
CMU1/CMU2 use 7 cameras; CMU3/CMU4 use 4 cameras with different placements. ▲ = best among optimization-based methods. R@500 = Recall@500 mm.
Also evaluated on Shelf & Campus (PCP)
| Method | Shelf | Campus | ||||||
|---|---|---|---|---|---|---|---|---|
| A1 | A2 | A3 | Avg | A1 | A2 | A3 | Avg | |
| Fully-supervised | ||||||||
| VoxelPose | 99.3 | 94.1 | 97.6 | 97.0 | 97.6 | 93.8 | 98.8 | 96.7 |
| Wu et al. | 99.3 | 96.5 | 97.3 | 97.7 | — | — | — | — |
| TEMPO | 99.3 | 95.1 | 97.8 | 97.4 | 97.7 | 95.5 | 97.9 | 97.3 |
| Self-supervised | ||||||||
| SelfPose3d | 97.2 | 90.3 | 97.9 | 95.1 | 92.5 | 82.2 | 89.2 | 87.9 |
| Optimization-based | ||||||||
| 3DPS | 75.3 | 69.7 | 87.6 | 77.5 | 93.5 | 75.7 | 84.4 | 84.5 |
| MvPose | 98.8 | 94.1 | 97.8 | 96.9 | 97.6 | 93.3 | 98.0 | 96.3 |
| COMPOSE-ILP Ours | 99.8 | 92.4 | 96.3 | 96.2 | 99.4 | 94.3 | 98.1 | 97.3 |
| COMPOSE-BP Ours | 99.8 | 92.4 | 96.3 | 96.2 | 99.4 | 94.3 | 93.6 | 95.7 |
Datasets from Belagiannis et al., 2014. Shelf — 4 people, heavy occlusion, 5 cameras. Campus — 3 people, outdoor, 3 cameras. A1/A2/A3 = Actor 1/2/3. ▲ = best among optimization-based methods.
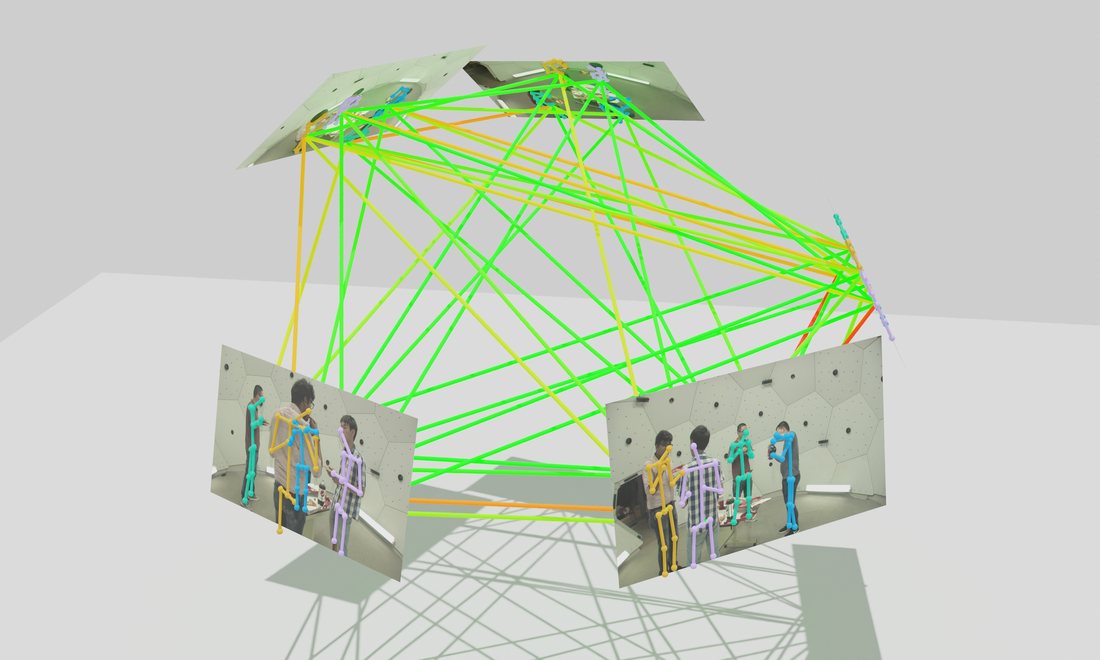
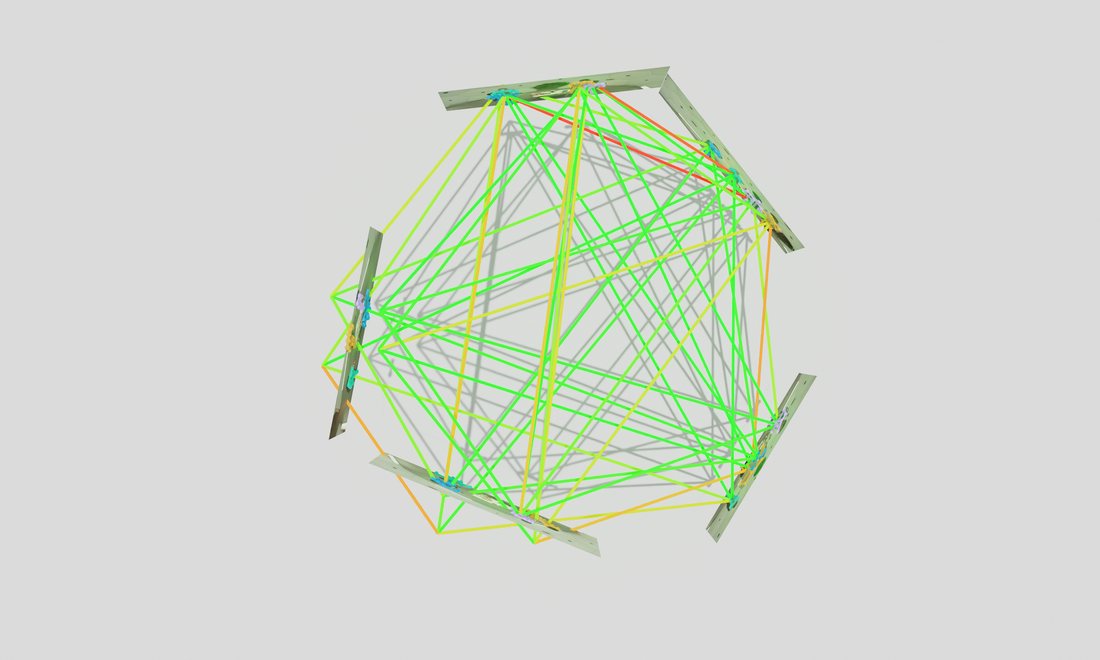
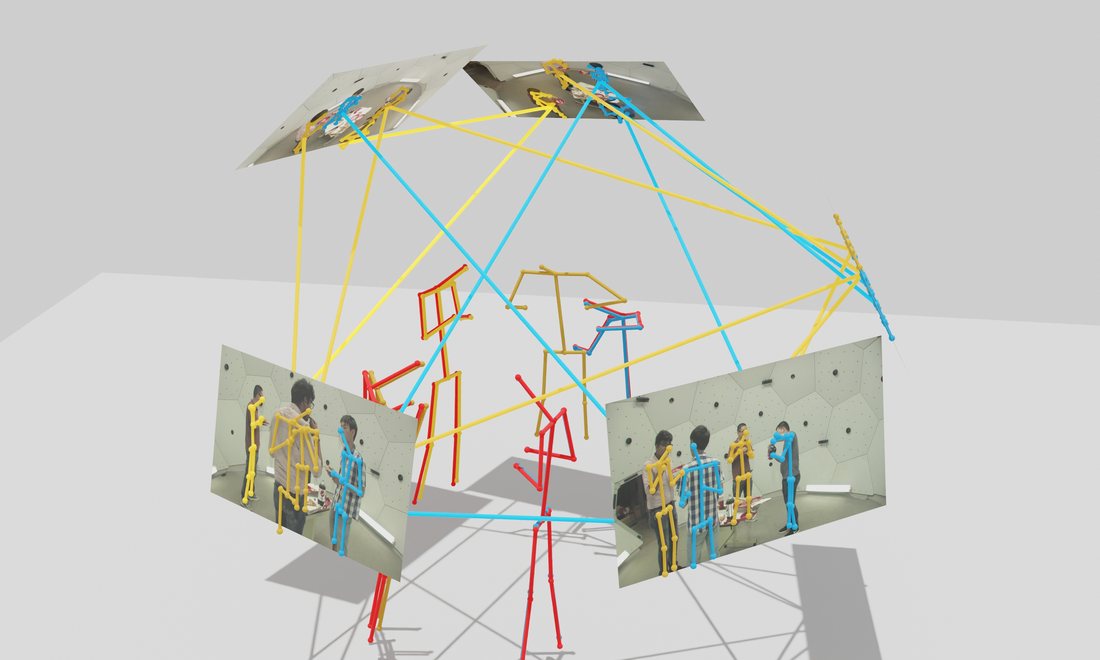
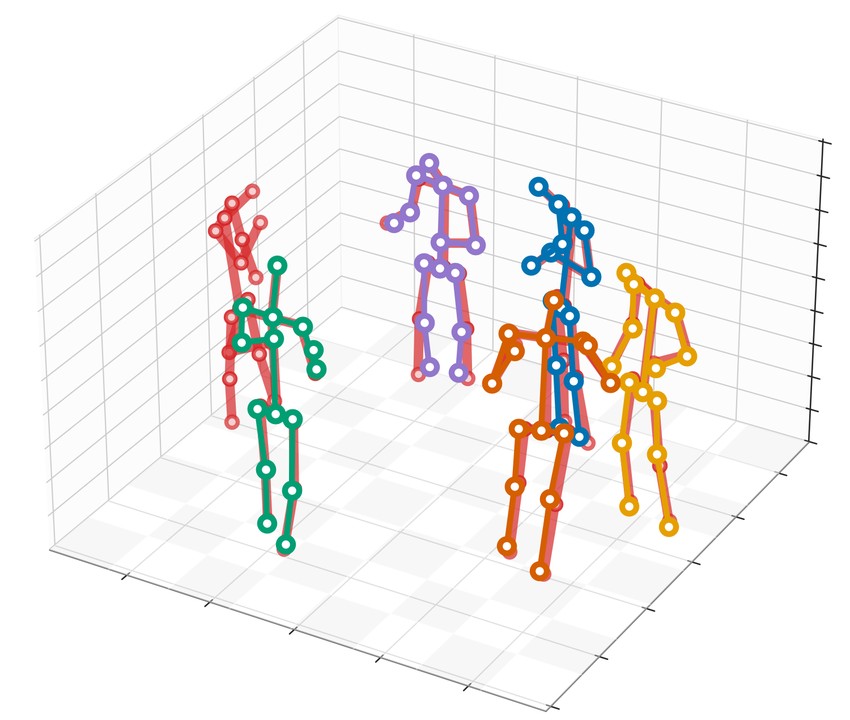
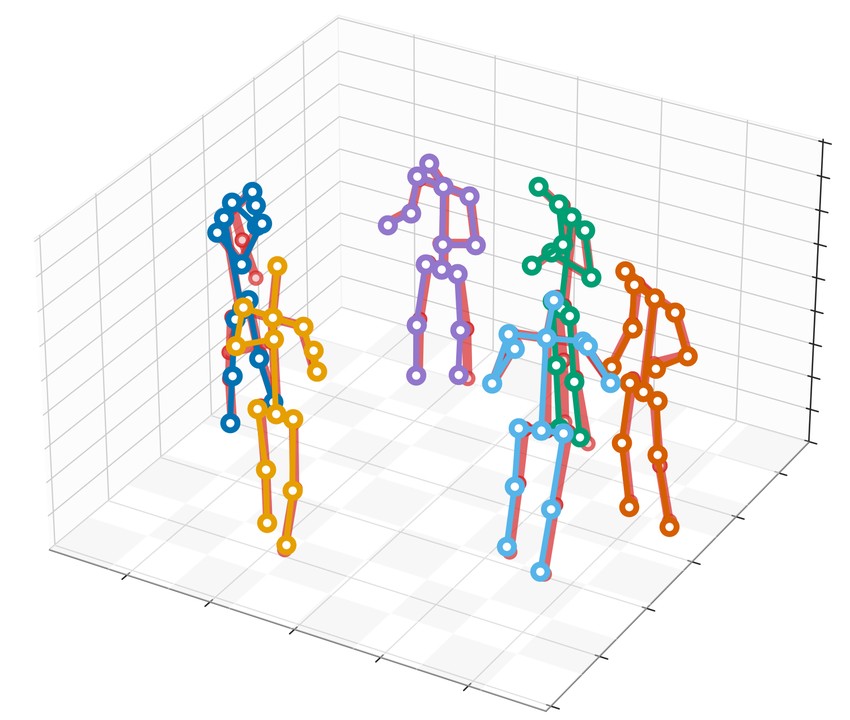
Qualitative reconstructions
A few calibrated camera views are enough to reconstruct the full 3D scene.
Multi-view input
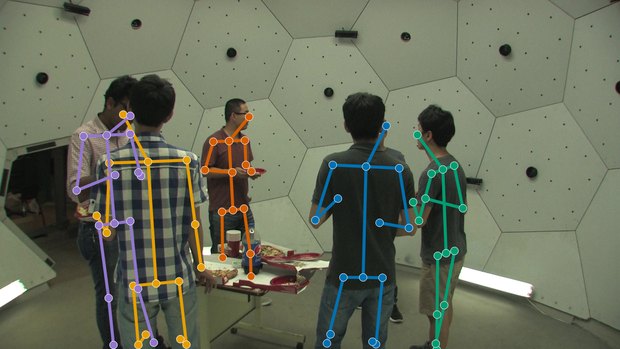

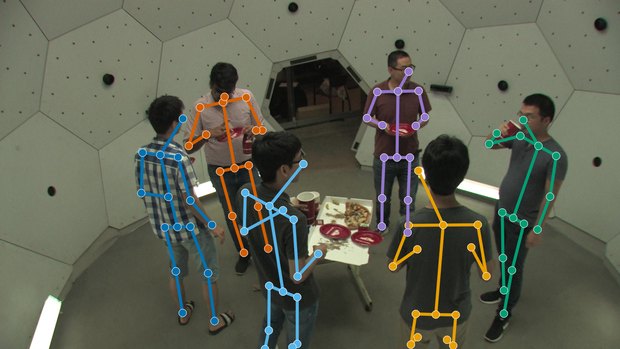


Whole-scene 3D reconstruction
Annotation noise on Shelf

Runtime and pruning efficiency
Belief Propagation tracks the exact ILP's accuracy closely while running in about 5 ms, regardless of how many cameras are used.
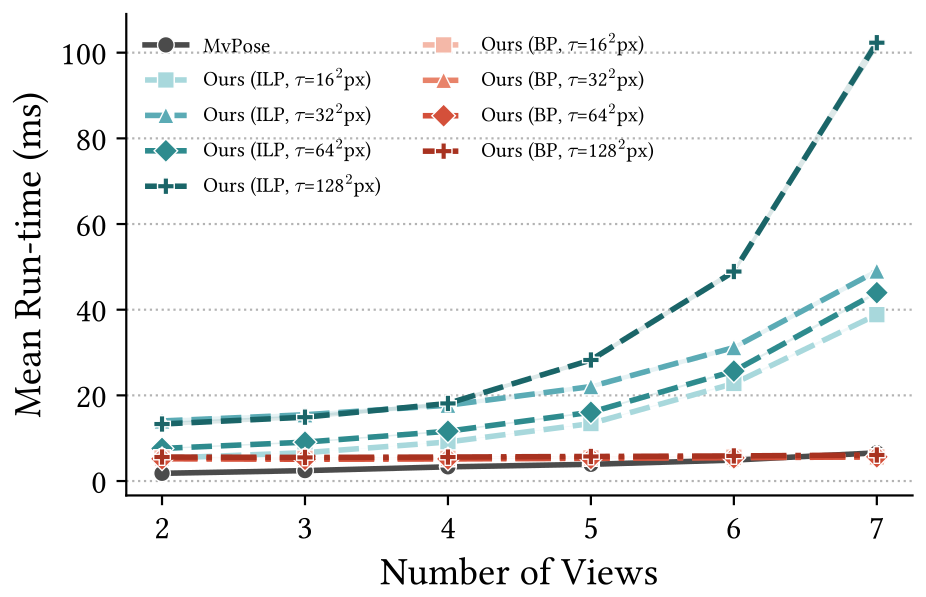
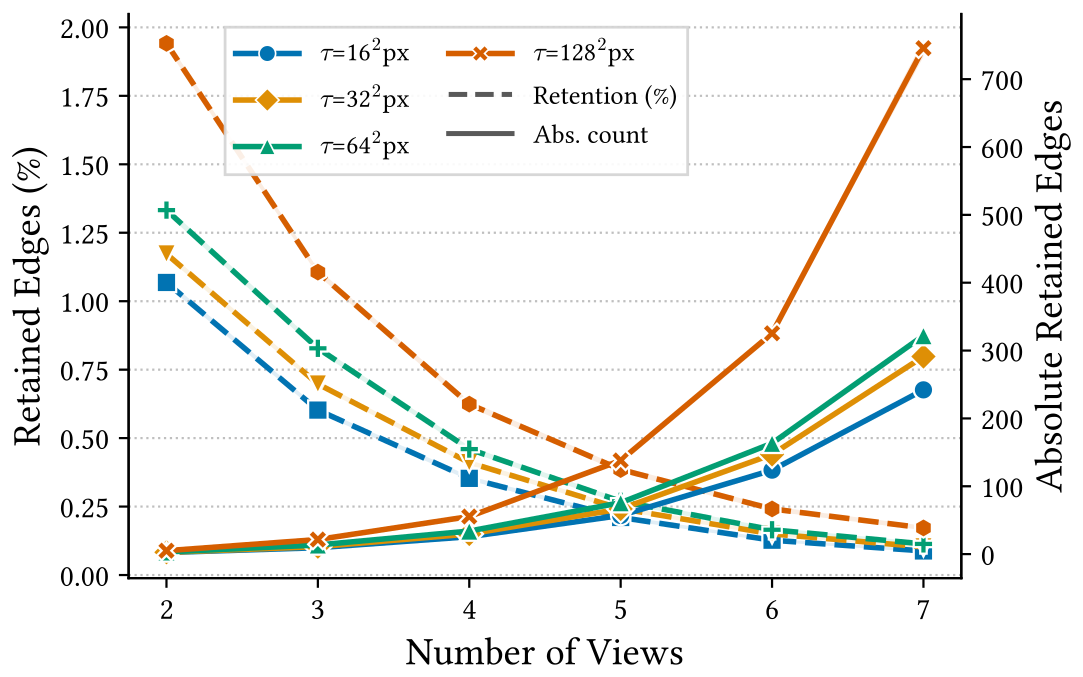
COMPOSE assumes calibrated cameras and an off-the-shelf 2D detector, and the exact ILP solver scales with the number of views (above) — Belief Propagation is the scalable alternative.
Cite this work
@article{wang2026compose, title = {COMPOSE: Hypergraph Cover Optimization for Multi-view 3D Human Pose Estimation}, author = {Tony Danjun Wang and Tolga Birdal and Nassir Navab and Lennart Bastian}, journal = {arXiv preprint arXiv:2601.09698}, year = {2026} }